What's in a Name? The Concepts and Language of Replication and Reproducibility
12 May 2015
Michael Clemens recently posted on the LSE Impact Blog about confusion surrounding the terminology used in discussing scientific replication. Reporting on a working paper, he documents dozens of conflicting definitions of key terms, including “replication,” “reproducibility,” “robustness,” “verification,” etc. We need a common vocabulary for talking about open science in order to solve the various - often unrelated - challenges that currently threaten scientific credibility. My goal here is to highlight that such a common language of open science may be challenging to construct precisely because of consequential disciplinary differences in the production of science. That said, we can increase the clarity of our discussions by being explicit about what scientific output is being created from what set of scientific inputs and the extent to which we expect identical, similar, and dissimilar inputs to create outputs identical, similar, or dissimilar to those of an original study.
The problem Clemens outlines is clear: without a common language to use when discussing the various aspects of a research study’s scientific robustness or credibility, it is hard to advance scientific literatures. More importantly, however, lacking some consensus on basic terminology means that participants in ongoing discussions about replication, reproducible research, and open science often talk past one another and propose solutions that can seem in appropriate solely because they are actually targeting conceptually distinct aspects of scientific practice. Clemens proposes the following matrix of terminology:
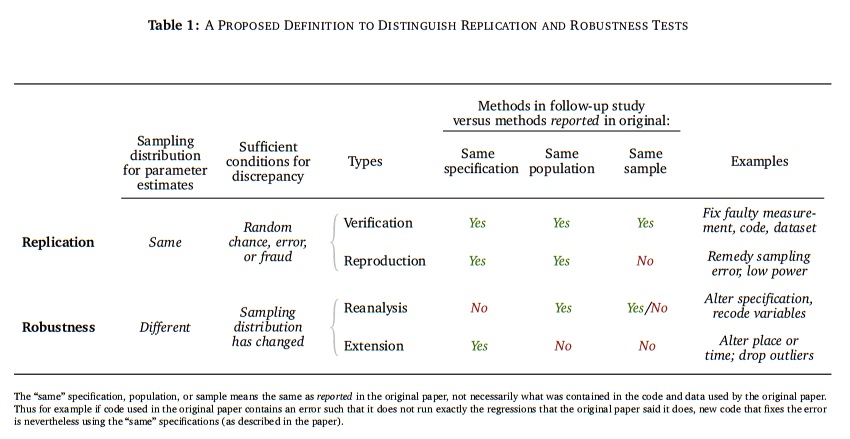
Lest we run the risk of creating yet another standard, I want to push back against the outline proposed by Clemens. His review of the semantic confusion is valuable, as is the typology he offers to make sense of it. I disagree with some of his labels, but as I thought about why I disagree with those labels, I am reminded that at least some portion of our disagreement (and the semantic confusion more broadly) is due to deeper-rooted disagreements about the nature of science. We need clear language, but we also need clear concept definition for what I call “reproduction” and “replication” (regardless of the labels we use to describe those concepts). Only then can we respond to and create policies around the underlying scientific issues at stake in these debates.
The Two Basic Concepts
When I talk about open science and the idea of reproducible research, I often define the core idea of reproducibility in the negative: that is, I distinguish the concept of reproducible research by highlighting what is not reproducible. Among the possible features of non-reproducible research are fraud, human error, lack of methodological transparency, privately held data, data loss, use of proprietary software, hardware, or file formats, measurement error, etc. Many things make research lose the property of being reproducible. I’m somewhat partial to the quip that “reproducible research is redundant. Irreproducible research just used to be known as ‘bullshit’.”. Okay, so that’s all good fun, but what is reproducible research, really?
In my own field of political science, we are hopelessly addicted to the term “replication” due to a 1995 article by Gary King titled “Replication, Replication”. The paper is an enormous contribution that has been the foundation for contemporary efforts to improve the transparency of analyses and data collection within our field, including the DA-RT initiative. But like Donald Rubin’s atrocious choice of terminology to describe the brilliant distinctions between types of missing data, the use of “replication” here is flawed. King’s argument was that published research should be reproducible: its analysis should be sufficiently clear and data made public so that other scholars can reproduce (i.e., “replicate”) the original results using the same data. King is talking about a form of reproducibility: given data (as originally collected) and a complete description of the steps needed to arrive at the results, could a reasonably competent person with a minimum of contemporary computer technology obtain numerical results that match those reported by the original authors. This is reproducible research.
Every time I read or hear about this article or the “replication” revolution it has spawned in political science, I cringe a little bit. I love what the article has done for open political science (e.g., leading to the creation and ever-expanding use of Dataverse), but I have always felt that King is talking about “reproducibility” and that “replication” is something reserved for new research, involving new data, new operationalizations, or new analytic methods rather than the pure reproduction of the original results. Should I be this bothered by what is ultimately semantics? Yes and no.
On the one hand, this is really a semantic complaint. If King’s article were retitled “Reproduction, Reproduction” and all references to it were changed from “replication” to “reproducibility,” “reproducible research”, or “reproduction” as appropriate, I would - at some surface level - be thrilled.
On the other hand, however, my discomfort with this language of open science stems from a rarely discussed lack of conceptual agreement (as opposed to shallow semantic agreement) about the core steps of the scientific process and which of those various steps should be transparent and in what ways. All of these terms refer to various forms of recreating an output from a given set of inputs. The reason why different labels are thought to refer to the same concept is that scholars often implicitly are referring to distinct inputs and outputs when they refer to the “replication” or “reproduction” or “verification” etc. of a research project.
Science involves (1) the observation of phenomena, (2) the translation and interpretation of those observations into data, (3) possibly the further restructuring or recoding of those data into a particular form, (4) the analysis of those data, (5) the production of particular outputs from those analyses (statistics, figures, tables, papers, presentations, etc.), and (6) the repetition of these steps to construct a cumulative, multi-study literature.
When we talk about “replication” or “reproducibility”, which of these stages of the scientific process are at stake? Potentially all of them. And that is the fundamental, conceptual disagreement underlying the confused terminology surrounding open science.
I think it is useful to restrict “reproduction” to the recreation of an output from a study’s original inputs. This means that I typically refer to “reproducibility” as the open, completely transparent sharing of the details of steps 3-5 in the above process (including shared data and analysis files). Similarly, I suggest we reserve replication for processes whereby new outputs are created from new inputs. In general, this means replication occurs at step 6, wherein some or all of steps 1-5 are repeated with new inputs in order to update our beliefs about the underlying phenomenon using new observations, data, or analysis.
I think this distinction simplifies things considerably: reproduction is reserved for the concept of recreating output from a shared input and replication is is reserved for the concept of creating new output from new input. But this basic dichotomy becomes problematic as soon as we apply it to different stages of the scientific process and different domains of scientific inquiry. What exactly is the difference between a “shared input” versus “new input”? The answers to this question are the reason that the terminology of open science is confused, and confusing.
Sources of Confusion
Consider a toy example of a physical science process. Think back to high school chemistry, if you can. A chemist performs a controlled experiment on a well-defined set of chemical inputs: let’s say some ocean-blue copper(II) sulfate and some pure iron. When combined in well-specified ratios, the output of this combination is iron(II) sulfate and a pure copper solid. Perhaps intrigued by this result, we want to know whether this research was “reproducible” - can we produce the same outputs from the same inputs? Because all atoms of iron and all molecules of copper(II) sulfate are functionally identical, we can reproduce this result by simply finding some new source of both inputs and follow the laboratory procedures to reproduce the same outputs. This is reproduction because the inputs are the “same” in the sense that while the individual atoms are different in the original and reproduced studies they are as-if identical. A “replication” of the original study is therefore indistinguishable from a “reproduction” because new inputs and the original inputs are functionally identical. In this context, there is not a conceptual distinction between reproduction and replication.
Now consider a toy example of a social science process. A scientist wants to know whether exposure to images of spiders induces a physiological response. A set of images are found and a set of participants recruited who are then shown the images, with their level of fear measured by galvanic skin response. Well-specified inputs (images, participants) create outputs (measured levels of fear). Analyzing the resulting data (a further input), graphs, tables, and summary statistics are produced (further outputs). Let’s apply the definitions of reproduction and replication here. If we want to “reproduce” this research, we might take the data as input and see whether (given those data and particular analysis code) we can produce the same graphs, tables, and statistics originally reported. If we can, the work is “reproducible” and not otherwise. But what if we back up one step in the scientific process and want to see whether we can reproduce the work taking the images and participants as input and see whether we can reproduce the same data outputs? This becomes tricky because we may not have access to those participants and the process of re-administering the study to these same participants may not produce the same data (perhaps due to desensitization, measurement error in the galvanic skin response device, other changes). The research might easily be reproducible with regard to the translation of data into claims but because it is social science and measurements almost definitionally cannot be recreated, the research is not reproducible with regard to the collection of data.
And what about replication in the social science example? If I want to replicate these results, I would obtain a similar set of inputs (perhaps the same images and a new set of participants) and follow identical protocol to measure galvanic skin response in the same way as the original study and analyze it in the same way. This is a replication in the sense that I am creating new output from new input. This becomes distinction from a reproduction because the inputs have changed. Thus in this context, the distinction between reproduction and replication is quite useful: if the initial research is reproducible it lends credibility to that research and if the research is replicable (i.e., the same or similar results are obtained from the replication study), then we might have much more confidence in our understanding of the phenomenon of physiological response.
So, is the only confusion between the natural sciences and the social sciences, then? No, not entirely. Social science research that takes historical observation as its initial inputs might be fully reproducible from step 1 (observation) all the way to step 5 (the production of publications, etc.). For example, a researcher might rely on administrative records (e.g., voter turnout records) collected in earlier years and other scholars can reproduce their translation of those records into a dataset. And by contrast, a physical scientist might want to reproduce observations of an astronomical phenomenon (e.g., solar flares) but be unable to do so because the phenomenon has changed since observations were originally made, thus restricting reproducibility to steps from 2 (or 3) to 5. Thus both physical and social sciences can be reproducible from the point of data analysis to publication, but depending on the nature of the underlying phenomena being studied, the ability to fully reproduce research from the point of observation (step 1) depends very much on the nature of the phenomena. If we can reproduce our original observations, then reproduction and replication are conceptually identical. If we cannot reproduce our original observations, then reproduction and replication take on quite distinct meanings.
If this distinction is so useful, why do we keep referring to reproduction of research as “replication” (especially in political science)? It seems King uses replication to refer largely to steps 4 and 5 because his article was written at a time when social scientists were largely working with large, publicly available datasets but when there was little infrastructure for the sharing of the computer code or software needed to recreate outputs from those data. King wanted his students to “replicate” the results without having access to the original scientists’ code or software, using whatever tools they had at their disposal. In that sense, “replication” is correct because an input (code) is produced anew in order to produce a new output (results, that hopefully match those originally reported). With decreased reliance on large datasets (e.g., the American National Election Studies) and the rise of data and analytic transparency, it is important that we limit “replication” to mean situations where new inputs are created and not use that term to refer to mere “reproduction” of publicly shared inputs.
Thinking about the toy examples described above, some situations may not offer a meaningful distinction between reproduction and replication, so in those contexts authors should be clear about what is of interest (transparency of how the original research produced particular outputs versus the creation of new scientific inputs meant to replicate the original findings). Thus, while I will continue to use reproduction to refer to the recreation of outputs from a shared set of inputs and replication to refer to the creation of outputs from new inputs, I see it as far more important that we have conceptual (if not semantic) clarity about the issues at-stake. This will greatly facilitate discussion of the implications reproduciblity and replicability for scientific practice.
The Implications of Terminology
Conversations about reproducibility and replication - and criticisms of the lack thereof - suggest implicit or explicit policy implications. When we talk about a study being irreproducible, it means that the credibility of that study’s findings should be reduced and its contribution should weigh less in our collective knowledge of the underlying phenomenon. Reproducibility (Clemens’ “verification”) is, as the earlier quip suggested, what distinguishes science from BS. Calls for reproducibility are implicitly claims that we should not trust irreproducible research.
When we talk about a study failing to replicate, however, the possible policy implications are more ambiguous. Indeed, Clemens’ efforts to create a typology of replication-related terms is rooted in an effort to classify various types of replication “failures”. I suggest three meaningful forms. A replication failure may mean (a) that the study’s data did not yield substantively similar findings when tested with alternative methods (Clemens’ “reanalysis”), (b) that the study’s described methods could not be reconstructed by other scientists (i.e., King’s “replication”), or (c) that new data (analyzed in the same or a different way) was inconsistent with the study’s findings (Clemens’ “extension”). Without being explicit about what step of the scientific process is being “replicated” (i.e., what input is being used to create what output), the implications of a “replication failure” are unclear. In case (a) or (b) we should be particularly suspect about using that study’s findings when accumulating our knowledge about the underlying phenomenon, whereas in case (c) we simply aggregate the findings of the original study and its replication(s). Replication failures of type (c) say nothing about the credibility of the original study, whereas replication failures of types (a) and (b) merit re-assessment of how that study contributes to our collective scientific understanding of a phenomenon.
- Failures as in case (a) are a healthy part of science, but they mean that we should discount or replace the original study’s findings with those of the “replication” (or average across them in some way) when aggregating our collective beliefs about the phenomenon. In this way, studies with superior methods applied to the same original data supplant rather than supplement our knowledge.
- Failures as in case (b), however, imply that disciplines and journals should set higher standards for reproducibility because the study is so intransparent as to lack credibility. In severe cases (e.g., apparent fraud or devastating human error), such failures may also merit retraction of publications and the removal of those findings from our accumulated knowledge.
- Failures as in case (c), in contrast with the other types, should be simply accepted as part of the cumulative scientific process without implications for the value of the original study. As we update our beliefs about the underlying phenomenon, we weight the contribution of the study and its replication(s) using some well-specified method of aggregation. It is in this type of replication failure that the confused terminology of open science becomes consequential. Psychology’s “replication crisis” often invites criticism of original studies - that a replication “failure” means the original study should not be trusted. This is incorrect. It means that we need to appropriately weigh all evidence: we need to update whatever beliefs we formed in response to the first study.
If one is concerned that type (c) replication failures are too common, then the policy implication has nothing to do reproducibility (these types of replication “failures” can happen in a world of perfectly reproducible or completely irreproducible research). Instead, the implication is modified standards for what merits publication (e.g., demanding higher powered research studies, explicitly publishing research regardless of the content of its findings, etc.).
Similarly, if one is concerned about reproducibility, the policy implications have nothing to do with replication. A lack of reproducibility demands greater transparency, data sharing, and publication contingent of the public archiving of data and code. Whether the findings of reproducible research “replicate” or not is irrelevant to whether we base our credibility judgments on the reproducibility and transparency of research.
As should hopefully be clear, when a specific input fails to produce the originally described output, actions should be taken. But the type of action taken depends on what steps of the scientific process (i.e., what inputs) are being recreated. Because one can reasonably use “replication” or “reproduction” to refer to multiple distinct parts of the scientific process, and those terms take on distinct meanings in different fields and types of research, careful use of language is needed when talking about principles of open science and their implications. I have offered what I hope are clear conceptual definitions of two ideas (labelled “reproduction” and “replication”) that I hope will facilitate future discussions. In particular, I hope that this attempt at conceptual clarity is useful for talking about the “replication crisis” and “replication failures” and how we as scientists should respond. There is no single reasonable response to a “replication failure” and the implications of replicability and reproducibility are quite distinct. We need to be clear - regardless of what terminology we use - about what output is being recreated (or failing to be recreated) from what input when we consider why reproducibility or replicability are important features of science.
 Except where noted, this website is licensed under a Creative Commons Attribution 4.0 International License. Views expressed are solely my own, not those of any current, past, or future employer.
Except where noted, this website is licensed under a Creative Commons Attribution 4.0 International License. Views expressed are solely my own, not those of any current, past, or future employer.